TBSS Tutorial#
TBSS stands for Tract-Based Spatial Statistics, a suite of tools for analyzing diffusion data. TBSS comes installed as part of the FSL software package. TBSS uses a tensor-fitting method to generate different measures of diffusion, such as fractional anisotropy (FA) and mean diffusivity (MD). Once these measurements are created, you can then extract them using ROI tools like you would for fMRI data.
The package also includes tools for correctying distortions in the diffusion data; in particular, the commands topup and eddy will remove distortions caused by eddy currents and magnetic field inhomogeneities.
Authors: Andrew Jahn & Monika Doerig
Citation:#
Andy’s Brain Book:
This notebook is based on the TBSS Analysis Tutorial chapter from Andy’s Brain Book (Jahn, 2022. doi:10.5281/zenodo.5879293)
Opensource Data from OpenNeuro:
Hannelore Aerts and Daniele Marinazzo (2018). BTC_preop. OpenNeuro Dataset ds001226
TBSS:
S.M. Smith, M. Jenkinson, H. Johansen-Berg, D. Rueckert, T.E. Nichols, C.E. Mackay, K.E. Watkins, O. Ciccarelli, M.Z. Cader, P.M. Matthews, and T.E.J. Behrens. Tract-based spatial statistics: Voxelwise analysis of multi-subject diffusion data. NeuroImage, 31:1487-1505, 2006.
For more details: https://ftp.nmr.mgh.harvard.edu/pub/dist/freesurfer/tutorial_packages/centos6/fsl_507/doc/wiki/TBSS.html
Before beginning, you may want to review the basics of diffusion imaging, which can be found here. The chapter will review the principles of diffusion, how they are used to generate diffusion-weighted images, and the advantages and disadvantages of fitting tensors to diffusion data.
Goals of This Tutorial#
This tutorial will show you how to analyze a sample dataset from start to finish using TBSS. We will be closely following the steps provided on the FSL TBSS website; the goal is to provide you with more experience in how to use this package, and use figures and videos to broaden your understanding of how it works and how it can be applied in other scenarios.
# Output CPU information:
!cat /proc/cpuinfo | grep 'vendor' | uniq
!cat /proc/cpuinfo | grep 'model name' | uniq
%%capture
! pip install nibabel matplotlib nilearn
Import Python Packages#
import subprocess
import nibabel as nib
import numpy as np
import matplotlib.pyplot as plt
import tempfile
import nilearn
Load Neuroimaging Software (MRtrix and TBSS)#
import lmod
await lmod.load('mrtrix3/3.0.4')
#await lmod.load('fsl/6.0.7.4')
await lmod.load('fsl/6.0.3') # Need to use this version in order for TBSS commands to work
await lmod.list()
['mrtrix3/3.0.4', 'fsl/6.0.3']
Try typing one of the commands from the library, such as fslinfo. If FSL has been installed correctly, you should see the help page printed by default when no arguments are passed to the command:
!fslinfo
Usage: /opt/fsl-6.0.3/bin/fslinfo <filename>
If this works without any errors, you are ready to begin analyzing the dataset.
Downloading the Dataset#
For this example, we will be preprocessing a dataset from openneuro.org called BTC preop. It includes data from patients with gliomas, patients with meningiomas, and a group of control subjects.
To download the data of one subject, excute the next cell:
PATTERN = "sub-CON02"
!datalad install https://github.com/OpenNeuroDatasets/ds001226.git
!cd ds001226 && datalad get $PATTERN
Cloning: 0%| | 0.00/2.00 [00:00<?, ? candidates/s]
Enumerating: 0.00 Objects [00:00, ? Objects/s]
Counting: 0%| | 0.00/25.9k [00:00<?, ? Objects/s]
Compressing: 0%| | 0.00/18.7k [00:00<?, ? Objects/s]
Receiving: 0%| | 0.00/25.9k [00:00<?, ? Objects/s]
Receiving: 6%|█▏ | 1.56k/25.9k [00:00<00:01, 15.5k Objects/s]
Receiving: 33%|██████▌ | 8.56k/25.9k [00:00<00:00, 37.3k Objects/s]
Receiving: 73%|██████████████▌ | 18.9k/25.9k [00:00<00:00, 63.6k Objects/s]
Resolving: 0%| | 0.00/4.30k [00:00<?, ? Deltas/s]
[INFO ] Filesystem allows writing to files whose write bit is not set.
[INFO ] Detected a crippled filesystem.
[INFO ] Disabling core.symlinks.
[INFO ] Entering an adjusted branch where files are unlocked as this filesystem does not support locked files.
[INFO ] scanning for annexed files (this may take some time)
[INFO ] Updating files: 16% (1007/5951)
[INFO ] Updating files: 17% (1012/5951)
[INFO ] Updating files: 18% (1072/5951)
[INFO ] Updating files: 19% (1131/5951)
[INFO ] Updating files: 20% (1191/5951)
[INFO ] Updating files: 21% (1250/5951)
[INFO ] Updating files: 22% (1310/5951)
[INFO ] Updating files: 23% (1369/5951)
[INFO ] Updating files: 24% (1429/5951)
[INFO ] Updating files: 25% (1488/5951)
[INFO ] Updating files: 26% (1548/5951)
[INFO ] Updating files: 27% (1607/5951)
[INFO ] Updating files: 28% (1667/5951)
[INFO ] Updating files: 29% (1726/5951)
[INFO ] Updating files: 30% (1786/5951)
[INFO ] Updating files: 31% (1845/5951)
[INFO ] Updating files: 32% (1905/5951)
[INFO ] Updating files: 33% (1964/5951)
[INFO ] Updating files: 33% (1965/5951)
[INFO ] Updating files: 34% (2024/5951)
[INFO ] Updating files: 35% (2083/5951)
[INFO ] Updating files: 36% (2143/5951)
[INFO ] Updating files: 37% (2202/5951)
[INFO ] Updating files: 38% (2262/5951)
[INFO ] Updating files: 39% (2321/5951)
[INFO ] Updating files: 40% (2381/5951)
[INFO ] Updating files: 41% (2440/5951)
[INFO ] Updating files: 42% (2500/5951)
[INFO ] Updating files: 43% (2559/5951)
[INFO ] Updating files: 44% (2619/5951)
[INFO ] Updating files: 45% (2678/5951)
[INFO ] Updating files: 46% (2738/5951)
[INFO ] Updating files: 47% (2797/5951)
[INFO ] Updating files: 48% (2857/5951)
[INFO ] Updating files: 48% (2884/5951)
[INFO ] Updating files: 49% (2916/5951)
[INFO ] Updating files: 50% (2976/5951)
[INFO ] Updating files: 51% (3036/5951)
[INFO ] Updating files: 52% (3095/5951)
[INFO ] Updating files: 53% (3155/5951)
[INFO ] Updating files: 54% (3214/5951)
[INFO ] Updating files: 55% (3274/5951)
[INFO ] Updating files: 56% (3333/5951)
[INFO ] Updating files: 57% (3393/5951)
[INFO ] Updating files: 58% (3452/5951)
[INFO ] Updating files: 59% (3512/5951)
[INFO ] Updating files: 60% (3571/5951)
[INFO ] Updating files: 61% (3631/5951)
[INFO ] Updating files: 62% (3690/5951)
[INFO ] Updating files: 63% (3750/5951)
[INFO ] Updating files: 63% (3757/5951)
[INFO ] Updating files: 64% (3809/5951)
[INFO ] Updating files: 65% (3869/5951)
[INFO ] Updating files: 66% (3928/5951)
[INFO ] Updating files: 67% (3988/5951)
[INFO ] Updating files: 68% (4047/5951)
[INFO ] Updating files: 69% (4107/5951)
[INFO ] Updating files: 70% (4166/5951)
[INFO ] Updating files: 71% (4226/5951)
[INFO ] Updating files: 72% (4285/5951)
[INFO ] Updating files: 73% (4345/5951)
[INFO ] Updating files: 74% (4404/5951)
[INFO ] Updating files: 75% (4464/5951)
[INFO ] Updating files: 76% (4523/5951)
[INFO ] Updating files: 77% (4583/5951)
[INFO ] Updating files: 78% (4642/5951)
[INFO ] Updating files: 79% (4702/5951)
[INFO ] Updating files: 79% (4734/5951)
[INFO ] Updating files: 80% (4761/5951)
[INFO ] Updating files: 81% (4821/5951)
[INFO ] Updating files: 82% (4880/5951)
[INFO ] Updating files: 83% (4940/5951)
[INFO ] Updating files: 84% (4999/5951)
[INFO ] Updating files: 85% (5059/5951)
[INFO ] Updating files: 86% (5118/5951)
[INFO ] Updating files: 87% (5178/5951)
[INFO ] Updating files: 88% (5237/5951)
[INFO ] Updating files: 89% (5297/5951)
[INFO ] Updating files: 90% (5356/5951)
[INFO ] Updating files: 91% (5416/5951)
[INFO ] Updating files: 92% (5475/5951)
[INFO ] Updating files: 93% (5535/5951)
[INFO ] Updating files: 94% (5594/5951)
[INFO ] Updating files: 95% (5654/5951)
[INFO ] Updating files: 95% (5662/5951)
[INFO ] Updating files: 96% (5713/5951)
[INFO ] Updating files: 97% (5773/5951)
[INFO ] Updating files: 98% (5832/5951)
[INFO ] Updating files: 99% (5892/5951)
[INFO ] Updating files: 100% (5951/5951)
[INFO ] Updating files: 100% (5951/5951), done.
[INFO ] Switched to branch 'adjusted/master(unlocked)'
[INFO ] Remote origin not usable by git-annex; setting annex-ignore
[INFO ] https://github.com/OpenNeuroDatasets/ds001226.git/config download failed: Not Found
[INFO ] access to 1 dataset sibling s3-PRIVATE not auto-enabled, enable with:
| datalad siblings -d "/neurodesktop-storage/TBSS_Example/ds001226" enable -s s3-PRIVATE
install(ok): /neurodesktop-storage/TBSS_Example/ds001226 (dataset)
Total: 0%| | 0.00/95.7M [00:00<?, ? Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 0%| | 0.00/8.31M [00:00<?, ? Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 1%| | 87.3k/8.31M [00:00<00:13, 626k Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 5%|▏ | 418k/8.31M [00:00<00:04, 1.62M Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 38%|█▏ | 3.13M/8.31M [00:00<00:00, 8.12M Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 69%|██ | 5.74M/8.31M [00:00<00:00, 13.1M Bytes/s]
Get sub-CON0 .. p_T1w.nii.gz: 0%| | 0.00/8.31M [00:00<?, ? Bytes/s]
Total: 9%|██▎ | 8.31M/95.7M [00:01<00:12, 7.12M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 0%| | 0.00/47.5M [00:00<?, ? Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 11%|▎ | 5.34M/47.5M [00:00<00:01, 26.7M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 22%|▋ | 10.5M/47.5M [00:00<00:01, 26.1M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 28%|▊ | 13.5M/47.5M [00:00<00:01, 27.2M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 35%|█ | 16.6M/47.5M [00:00<00:01, 28.2M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 42%|█▏ | 19.7M/47.5M [00:00<00:00, 29.2M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 48%|█▍ | 23.0M/47.5M [00:00<00:00, 30.3M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 55%|█▋ | 26.1M/47.5M [00:00<00:00, 30.5M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 65%|█▉ | 31.1M/47.5M [00:01<00:00, 28.0M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 72%|██▏| 34.2M/47.5M [00:01<00:00, 28.6M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 79%|██▎| 37.3M/47.5M [00:01<00:00, 29.3M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 85%|██▌| 40.5M/47.5M [00:01<00:00, 29.8M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 92%|██▊| 43.6M/47.5M [00:01<00:00, 30.2M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 99%|██▉| 46.8M/47.5M [00:01<00:00, 30.8M Bytes/s]
Get sub-CON0 .. P_dwi.nii.gz: 0%| | 0.00/47.5M [00:00<?, ? Bytes/s]
Total: 58%|███████████████▏ | 55.8M/95.7M [00:03<00:02, 18.0M Bytes/s]
Get sub-CON0 .. A_dwi.nii.gz: 0%| | 0.00/1.16M [00:00<?, ? Bytes/s]
Get sub-CON0 .. A_dwi.nii.gz: 0%| | 0.00/1.16M [00:00<?, ? Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 0%| | 0.00/38.7M [00:00<?, ? Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 15%|▍ | 5.75M/38.7M [00:00<00:01, 28.8M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 22%|▋ | 8.65M/38.7M [00:00<00:01, 28.8M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 30%|▉ | 11.7M/38.7M [00:00<00:00, 29.3M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 38%|█▏ | 14.6M/38.7M [00:00<00:00, 29.3M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 45%|█▎ | 17.6M/38.7M [00:00<00:00, 29.4M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 53%|█▌ | 20.5M/38.7M [00:00<00:00, 29.4M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 61%|█▊ | 23.5M/38.7M [00:00<00:00, 29.4M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 68%|██ | 26.4M/38.7M [00:00<00:00, 29.4M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 76%|██▎| 29.4M/38.7M [00:01<00:00, 29.6M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 84%|██▌| 32.5M/38.7M [00:01<00:00, 29.8M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 100%|██▉| 38.6M/38.7M [00:01<00:00, 30.1M Bytes/s]
Get sub-CON0 .. _bold.nii.gz: 0%| | 0.00/38.7M [00:00<?, ? Bytes/s]
get(ok): sub-CON02/ses-preop/anat/sub-CON02_ses-preop_T1w.nii.gz (file) [from s3-PUBLIC...]
get(ok): sub-CON02/ses-preop/dwi/sub-CON02_ses-preop_acq-AP_dwi.nii.gz (file) [from s3-PUBLIC...]
get(ok): sub-CON02/ses-preop/dwi/sub-CON02_ses-preop_acq-PA_dwi.nii.gz (file) [from s3-PUBLIC...]
get(ok): sub-CON02/ses-preop/func/sub-CON02_ses-preop_task-rest_bold.nii.gz (file) [from s3-PUBLIC...]
get(ok): sub-CON02 (directory)
action summary:
get (ok: 5)
#
If you want to download more subjects, here is an example how to get 4 controls and 4 patients:
PATTERN_CONTROLS="sub-CON0[1-4]"
PATTERN_PATIENTS="sub-PAT0[1-4]"
! datalad install https://github.com/OpenNeuroDatasets/ds001226.git
! cd ds001226 && datalad get $PATTERN_CONTROLS $PATTERN_PATIENTS
Looking at the Data#
In order to view the data, we will navigate to the folder sub-CON02/ses-preop/dwi, which contains the diffusion data. We import the os package to change directories, and also to list the contents of that directory:
import os
os.chdir("/home/jovyan")
# Save the original directory
original_dir = os.getcwd()
# Navigate to the diffusion data
os.chdir("neurodesktop-storage/TBSS_Example/ds001226/sub-CON02/ses-preop/dwi")
os.listdir()
['sub-CON02_ses-preop_acq-PA_dwi.nii.gz',
'sub-CON02_ses-preop_acq-PA_dwi.json',
'sub-CON02_ses-preop_acq-AP_dwi.json',
'sub-CON02_ses-preop_acq-PA_dwi.bval',
'sub-CON02_ses-preop_acq-AP_dwi.bvec',
'sub-CON02_ses-preop_acq-AP_dwi.nii.gz',
'sub-CON02_ses-preop_acq-AP_dwi.bval',
'sub-CON02_ses-preop_acq-PA_dwi.bvec']
To make the rest of the example easier to read as well, use the mv command to rename the .bval and .bvec files:
! mv sub-CON02_ses-preop_acq-AP_dwi.bvec sub-02_AP.bvec
! mv sub-CON02_ses-preop_acq-AP_dwi.bval sub-02_AP.bval
! mv sub-CON02_ses-preop_acq-PA_dwi.bvec sub-02_PA.bvec
! mv sub-CON02_ses-preop_acq-PA_dwi.bval sub-02_PA.bval
! fslinfo sub-CON02_ses-preop_acq-AP_dwi.nii.gz
data_type INT16
dim1 96
dim2 96
dim3 60
dim4 102
datatype 4
pixdim1 2.500000
pixdim2 2.500000
pixdim3 2.500000
pixdim4 8.700000
cal_max 0.000000
cal_min 0.000000
file_type NIFTI-1+
Note that, since this is a 4-dimensional dataset, the last dimension is time; in other words, this file contains 102 volumes, each one with dimensions of 96 x 96 x 60 voxels. The last dimension of the Voxel size field - which in this case has a value of 8.7 - indicates the time it took to acquire each volume, the repetition time, or TR.
Bvals and Bvecs#
The other files we need to check are the bvals and bvecs files. Briefly, the bvals contain a single number per volume that indicates how large of a diffusion gradient was applied to the data; and the bvecs file contains a triplet of numbers per volume that shows in what directions the gradients were applied. In general, volumes with larger b-values will be more sensitive to diffusion changes, but the images will also be more susceptible to motion and physiological artifacts.
The most important check is to ensure that the number of bvals and the number of bvecs are the same as the number of volumes in the dataset. For example, we can find the number of volumes in the sub-CON02_ses-preop_acq-AP_dwi.nii.gz dataset by typing:
! fslinfo sub-CON02_ses-preop_acq-AP_dwi.nii.gz | awk 'FNR == 5 {print $2}'
102
Which returns a value of 102, the number in the 4th field of the dimensions header that corresponds to the number of time-points, or volumes, in the dataset. We then compare this with the number of bvals and bvecs by using awk to count the number of columns in each text file:
! awk '{print NF; exit}' sub-02_AP.bvec
! awk '{print NF; exit}' sub-02_AP.bval
102
102
If the number of volumes in your dataset and the number of bvals and bvecs do not match, you should check with your scan technician about the discrepancy; the files may not have been properly uploaded to the server, or maybe the diffusion-weighted image wasn’t acquired correctly.
Visualization#
In order to view the image, we will use a couple of different packages, and you can determine which one you prefer. The first one we will use it matplotlib, which was loaded earlier in this notebook. In the code below, we will temporarily convert the data to NIFTI format and plot 3 volumes with Matplotlib.
dwi_file = 'sub-CON02_ses-preop_acq-AP_dwi.nii.gz'
# Load the NIfTI file
nii_image = nib.load(dwi_file)
data = nii_image.get_fdata()
# Define volume indices for the three volumes you want to display
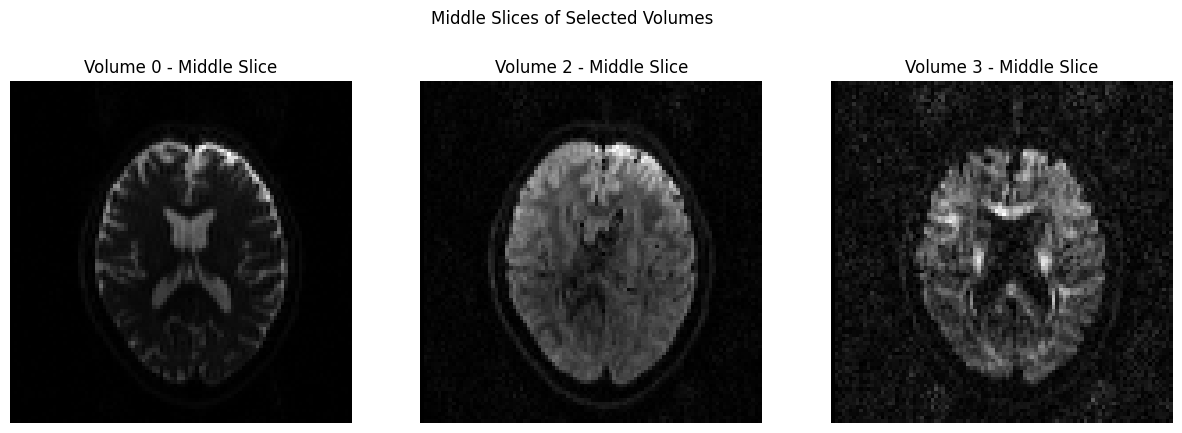
volume_indices = [0, 2, 3]
slice_index = data.shape[2] // 2 # Choose the middle slice for visualization
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, vol_idx in enumerate(volume_indices):
# Extract the middle slice from the selected volume and rotate it 90°
rotated_slice = np.rot90(data[:, :, slice_index, vol_idx])
axes[i].imshow(rotated_slice, cmap="gray")
axes[i].set_title(f"Volume {vol_idx} - Middle Slice")
axes[i].axis("off")
plt.suptitle("Middle Slices of Selected Volumes")
plt.show()
Another way to view these images is through nilearn, which contains a plotting library. The code below will import the necessary packages, and then extract and plot the first volume of the time-series. This opens an interactive plot upon which you can click and drag your mouse cursor. Note in particular that the frontal pole is slightly deformed and squished inwards; we will fix that by using topup.
from nilearn import plotting
from nilearn import image
dwi_image = 'sub-CON02_ses-preop_acq-AP_dwi.nii.gz'
print(image.load_img(dwi_image).shape)
first_dwi_volume = image.index_img(dwi_image,0) # Load first volume of DWI time-series
plotting.view_img(first_dwi_volume, bg_img=False, threshold=None)
(96, 96, 60, 102)
/home/jovyan/.local/lib/python3.12/site-packages/nilearn/image/resampling.py:591: UserWarning: Casting data from int32 to float32
warnings.warn(f"Casting data from {data.dtype.name} to {aux}")
topup#
The first preprocessing step we will do is topup, which is designed to correct distortions caused by magnetic field inhomogeneities. These inhomogeneities are particularly noticeable near the sinuses and around the edges of the brain, especially along the axis of the phase-encoding direction. For example, if we collect our images using an anterior-to-posterior phase-encoding direction, the inhomogeneities will be most noticeable at the front and back of the head, as you can see in the image above.
These inhomogeneities are easiest to detect in the images that do not have any diffusion-weighting applied; in other words, the images with a b-value of 0. In this dataset, we have seen that the first volume of the AP and PA datasets both have a b-value of 0. Consequently, we will extract these volumes using the command fslroi:
!fslroi sub-CON02_ses-preop_acq-AP_dwi.nii.gz AP 0 1
!fslroi sub-CON02_ses-preop_acq-PA_dwi.nii.gz PA 0 1
This creates two new files, “AP.nii.gz” and “PA.nii.gz”. We then combine them using fslmerge:
!fslmerge -t AP_PA AP.nii.gz PA.nii.gz
to create the file “AP_PA.nii.gz”. Try opening this file in fsleyes and toggling back and forth between the two volumes to see how they have been combined into a single dataset.
from IPython.display import display, clear_output
import time
img = nib.load("AP_PA.nii.gz")
data = img.get_fdata()
mid_slice = data.shape[1] // 2 # sagittal slice
for i in range(10): # flip 10 times
for vol in range(2):
plt.imshow(data[:, mid_slice, :, vol].T, cmap='gray', origin='lower')
plt.title(f"{'AP' if vol == 0 else 'PA'} Volume")
display(plt.gcf())
time.sleep(1.0) #flip every second
clear_output(wait=True)
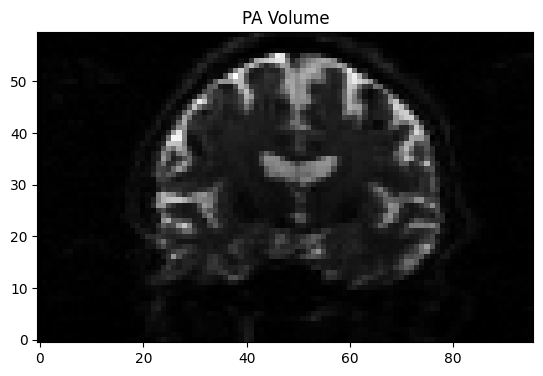
We will also need to create a file that indicates the phase-encoding direction and the read-out time. Using a text editor of your choice, or simply using Python code, you can write the following numbers into a file called acq_param.txt:
text_to_save = "0 1 0 0.0266003 \n0 -1 0 0.0266003"
file_path = "acq_param.txt"
with open(file_path, 'w') as file:
file.write(text_to_save)
To check whether the numbers were saved correctly, type:
with open('acq_param.txt', 'r') as f:
print(f.read())
0 1 0 0.0266003
0 -1 0 0.0266003
The first three numbers in the first row represent the phase-encoding along the x-, y-, and z-dimensions. Since the first volume was acquired in the A-P direction, we place a “1” in the second column. In the next row, since the second image in this dataset was acquired in the opposite direction, we use a value of “-1”. The last column is the read-out time, in milliseconds; if it’s the same for both images, you can set it to “1”. Otherwise, replace it with the exact read-out time for each volume separately. For the current dataset, this number can be found in the “TotalReadOutTime” field of the “.json” file in the dwi directory.
Once you have all of these ingredients, you are ready to run topup to estimate the field inhomogeneity:
!topup --imain=AP_PA.nii.gz --datain=acq_param.txt --config=b02b0.cnf --out=AP_PA_topup
The option –config=b02b0.cnf may look out of place, since we didn’t create a file with that name; do not worry, however, since this is a default file that is included in FSL’s libraries and will be automatically detected if you include it. The configuration parameters specified in the file are designed to work with most diffusion imaging data, so don’t change it unless you have a custom configuration file you created yourself.
After a few minutes, you will see a few new files, including one called AP_PA_topup_fieldcoef.nii.gz. These are the inhomogeneity estimations, which you can view in fsleyes if you like. We can now apply them to the original A-P phase-encoded data, which we will be using for our diffusion analysis:
!applytopup --imain=sub-CON02_ses-preop_acq-AP_dwi.nii.gz --inindex=1 --datain=acq_param.txt --topup=AP_PA_topup --method=jac --out=AP_Cor
This uses the fieldmap estimated above, as specified by the –topup option, to unwarp the A-P data. The inindex option, which we have set to 1, indicates that we are applying the unwarping to the phase-encoded image represented in the first line of the “acq_param.txt” file. –method=jac uses jacobin modulation, and –out is used to specify a label for the output image.
When it is finished, you can open the image “AP_Cor.nii.gz” in fsleyes (or, alternatively, you can use the Python code below). Load the raw “sub-CON02_ses-preop_acq-AP_dwi.nii.gz” image as well and toggle between the two using the eye icon in the GUI in order to see the image before and after unwarping. If you are satisfied with the results, we can move on to the next preprocessing step of fitting the tensors.
dwi_topup_image = 'AP_Cor.nii.gz'
print(image.load_img(dwi_topup_image).shape)
first_topup_volume = image.index_img(dwi_topup_image,0) # Load first volume of DWI time-series
plotting.view_img(first_topup_volume, bg_img=False, threshold=None)
(96, 96, 60, 102)
/home/jovyan/.local/lib/python3.12/site-packages/nilearn/image/resampling.py:591: UserWarning: Casting data from int32 to float32
warnings.warn(f"Casting data from {data.dtype.name} to {aux}")
/home/jovyan/.local/lib/python3.12/site-packages/nilearn/_utils/niimg.py:61: UserWarning: Non-finite values detected. These values will be replaced with zeros.
warn(
Compare this to the previous unwarped image, for example, slice Z=30, to see how the distortions were corrected:
plotting.view_img(first_dwi_volume, bg_img=False, threshold=None)
/home/jovyan/.local/lib/python3.12/site-packages/nilearn/image/resampling.py:591: UserWarning: Casting data from int32 to float32
warnings.warn(f"Casting data from {data.dtype.name} to {aux}")
orig = nib.load('sub-CON02_ses-preop_acq-AP_dwi.nii.gz').get_fdata()[..., 0]
corr = nib.load('AP_Cor.nii.gz').get_fdata()[..., 0]
slice = 20 #mid slice = orig.shape[2] // 2 # axial slice
for i in range(10):
for vol, title, data in zip([0, 1], ["Warped", "Unwarped"], [orig, corr]):
plt.imshow(data[:, :, slice].T, cmap='hot', origin='lower')
plt.title(f"{title} DWI (b=0)")
display(plt.gcf())
time.sleep(1)
clear_output(wait=True)
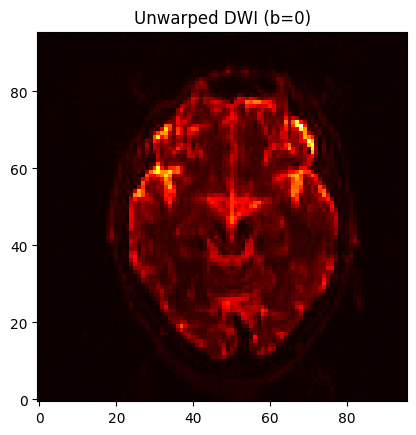
To run the following commands to fit the tensors, we will need to create a mask, which should be based on the corrected dataset that we generated using topup in the previous section. We will begin by extracting the first volume of that dataset using fslroi:
!fslroi AP_Cor.nii.gz AP_1stVol 0 1
And then use bet to create a mask from that image:
!bet AP_1stVol.nii.gz AP_brain -m -f 0.2
plotting.view_img('AP_brain_mask.nii.gz', bg_img=False, threshold=None, resampling_interpolation='nearest', colorbar=False)
from ipyniivue import NiiVue #depending on the version, could be AnyNiivue instead
nv = NiiVue()
nv.load_volumes([{"path": 'AP_brain_mask.nii.gz'}])
nv
Fitting the Tensors#
Now that we have unwarped the data, we are ready to fit a tensor at each voxel, representing the direction and the magnitude of diffusion. For a review of what a tensor is and how it is modeled, see the section “Putting it all together: Modeling the tensor” in this chapter.
The easiest way to fit the tensors is to use the Graphical User Interface by typing the command Fdt_gui, selecting DTIFIT Reconstruct diffusion tensors from the dropdown menu, and filling in each of the fields. You can also run it from the command line by using the following code:
!dtifit --data=AP_Cor.nii.gz --out=dti --mask=AP_brain_mask.nii.gz --bvecs=sub-02_AP.bvec --bvals=sub-02_AP.bval
0 96 0 96 0 60
0 slices processed
1 slices processed
2 slices processed
3 slices processed
4 slices processed
5 slices processed
6 slices processed
7 slices processed
8 slices processed
9 slices processed
10 slices processed
11 slices processed
12 slices processed
13 slices processed
14 slices processed
15 slices processed
16 slices processed
17 slices processed
18 slices processed
19 slices processed
20 slices processed
21 slices processed
22 slices processed
23 slices processed
24 slices processed
25 slices processed
26 slices processed
27 slices processed
28 slices processed
29 slices processed
30 slices processed
31 slices processed
32 slices processed
33 slices processed
34 slices processed
35 slices processed
36 slices processed
37 slices processed
38 slices processed
39 slices processed
40 slices processed
41 slices processed
42 slices processed
43 slices processed
44 slices processed
45 slices processed
46 slices processed
47 slices processed
48 slices processed
49 slices processed
50 slices processed
51 slices processed
52 slices processed
53 slices processed
54 slices processed
55 slices processed
56 slices processed
57 slices processed
58 slices processed
59 slices processed
When it is done, load the files dti_V1 and dti_FA in fsleyes. With the file dti_V1 highlighted, click on the “Modulate by” menu and select dti_FA. This will create an image that shows the primary direction of diffusion at each voxel, with red representing diffusion that is primarily left to right, green representing back to forward, and blue representing bottom to top. If the tensors were fit correctly, you should see mostly red in the corpus callosum and blue in the corona radiata, since those fiber bundles are mostly restricted to the left to right and bottom to top directions.
TBSS Preprocessing#
Fortunately, each of the preprocessing steps is simple and straightforward to run; each command has the string “tbss” in it, with a number indicating which step to do, and in which order.
First, within the dwi directory create a new directory called tbss and then copy the FA image into that directory:
!mkdir tbss
!cp dti_FA.nii.gz tbss
os.chdir('tbss')
Now that you are in the directory, we just need to run through each tbss preprocessing step. The first one, tbss_1_preproc, will clean up the FA images by removing the brighter voxels around the edges of the brain, and then placing the image into a folder called FA:
!tbss_1_preproc dti_FA.nii.gz
processing dti_FA
Now running "slicesdir" to generate report of all input images
Finished. To view, point your web browser at
file:/neurodesktop-storage/TBSS_Example/ds001226/sub-CON02/ses-preop/dwi/tbss/FA/slicesdir/index.html
os.getcwd()
'/neurodesktop-storage/TBSS_Example/ds001226/sub-CON02/ses-preop/dwi/tbss'
Next, we register the data to MNI space to calculate the warps needed for the transforms:
!tbss_2_reg -T
dti_FA_FA_to_target
5693
With the “-T” option indicating that we will use the FA template “FMRIB58_FA_1mm”.
The following step will apply the warps and bring the FA data to MNI space:
!tbss_3_postreg -S
using pre-chosen target for registration
transforming all FA images into MNI152 space
dti_FA_FA
merging all upsampled FA images into single 4D image
creating valid mask and mean FA
skeletonising mean FA
now view mean_FA_skeleton to check whether the default threshold of 0.2 needs changing, when running:
tbss_4_prestats <threshold>
The “-S” option will create files called “mean_FA” and “mean_FA_skeleton” based on the mean of all of the subjects that have been analyzed in with the previous steps. Since we only have one subject in this case, it will be the same as the single FA image that we have been processing.
You can check the normalization of the FA data by typing the following:
plotting.view_img('stats/mean_FA.nii.gz', threshold=0.3)
/home/jovyan/.local/lib/python3.12/site-packages/numpy/core/fromnumeric.py:771: UserWarning: Warning: 'partition' will ignore the 'mask' of the MaskedArray.
a.partition(kth, axis=axis, kind=kind, order=order)
# Load FA map
fa_nii = nib.load("./FA/dti_FA_FA.nii.gz")
fa_data = fa_nii.get_fdata()
# Load V1 map
v1_nii = nib.load("../dti_V1.nii.gz")
v1_data = v1_nii.get_fdata() # shape = (X, Y, Z, 3)
# Scale eigenvectors by FA to get color FA map (DEC map)
dec_data = np.abs(v1_data) * fa_data[..., None]
# Prepare header and save new image
hdr = v1_nii.header.copy()
hdr.set_intent("vector")
hdr["intent_name"] = b"RGB"
dec_nii = nib.Nifti1Image(dec_data.astype(np.float32), v1_nii.affine, header=hdr)
nib.save(dec_nii, "./FA/dti_DEC.nii.gz")
nv = NiiVue()
nv.load_volumes([{"path": './FA/dti_DEC.nii.gz'},
])
nv
Epilogue#
This demonstration has showed you how to unwarp and preprocess a diffusion-weighted image for a single subject, which generates an FA image which you can use for statistical analysis. As an exercise, trying adapting this notebook to analyze a handful of subjects from the same dataset, calculate their FA images, and then submit them to a group-level analysis.