How to add new tools
How to add new tools to neurodesk
Guiding principles
To decide if a tool should be packaged in a Neurocontainers or be installed in the Neurodesktop container, we are currently following these guiding principles:
1) Neurodesk is a Platform, Not a Package Manager: We don’t distribute tools that can be easily installed via standard package managers.
2) Multiple versions of tools: Neurodesk supports the use of multiple versions of a tool in parallel via lmod. If a tool doesn’t support this, follow this instruction to package it in Neurocontainers.
3) Inter-Container Tool Linking: Neurodesk is designed to facilitate the linking of tools from different containers, such as workflow managers like nipype or nextflow. Therefore, if a tool is needed to coordinate various container-tools, create an issue to have it installed directly in the Neurodesktop container.
Examples:
| easy install | coordinates containers | small in size | latest version is ok | useful to most users | Conclusion |
|---|
| git | yes | yes | yes | yes | yes | neurodesktop |
| lmod | no | yes | yes | yes | yes | neurodesktop |
| itksnap | yes | no | yes | yes | yes | neurocontainer |
| convert3D | yes | no | yes | no | no | neurocontainer |
| fsl | no | no | no | no | no | neurocontainer |
Follow these instructions to add new tools: https://www.neurodesk.org/developers/new_tools/manual_build
1 - New tool
How to contribute a new container.
We have launched our new container build system. Some documentation can already be found here: https://github.com/NeuroDesk/neurocontainers/tree/main/builder
We have also released a web browser UI to create your own Neurocontainer: https://www.neurodesk.org/neurocontainers-ui/
We are currently building the detailed documentation for this, but documenttaion is also embedded in the UI. If you have any issues, please
Need Help?
If you have questions or would like feedback before submitting:
We appreciate your contribution to the Neurodesk community and reproducible science.
2 - Update tool in Neurodesk
Step-by-step instructions on how to update an existing NeuroDesk tool container.
Updating an existing container is quite easy with this new build system.
Here is a step-by-step on how to procede by modifying the .yaml file. It is also possible to edit the containers by using our newly released web browser UI : https://www.neurodesk.org/neurocontainers-ui/
There’s a detailled version below including screenshots and an example.
Condensed version
- Access the Neurodesk Containers repository
- Fork the repository
- Using your preferred development environment (such as VS Code locally or GitHub Codespaces), make changes to the desired container.
Each tool has its own folder inside the recipes/ directory, and inside that folder, you will find the corresponding build.yaml file.
Editing the build.yaml
Open the build.yaml file. Make the necessary updates to:
- Software version numbers
- Dependencies
- Download links
- Build instructions (if needed)
- Validate your changes
Make sure your changes are valid.
In the terminal, run:
./builder/build.py generate <toolname>
#This second step can take some time
./builder/build.py generate <toolname> --recreate --build --test
- Commit and push your changes
- Create a pull request
Detailled version
1. Access the Neurodesk Containers
Navigate to the Neurocontainers repository:
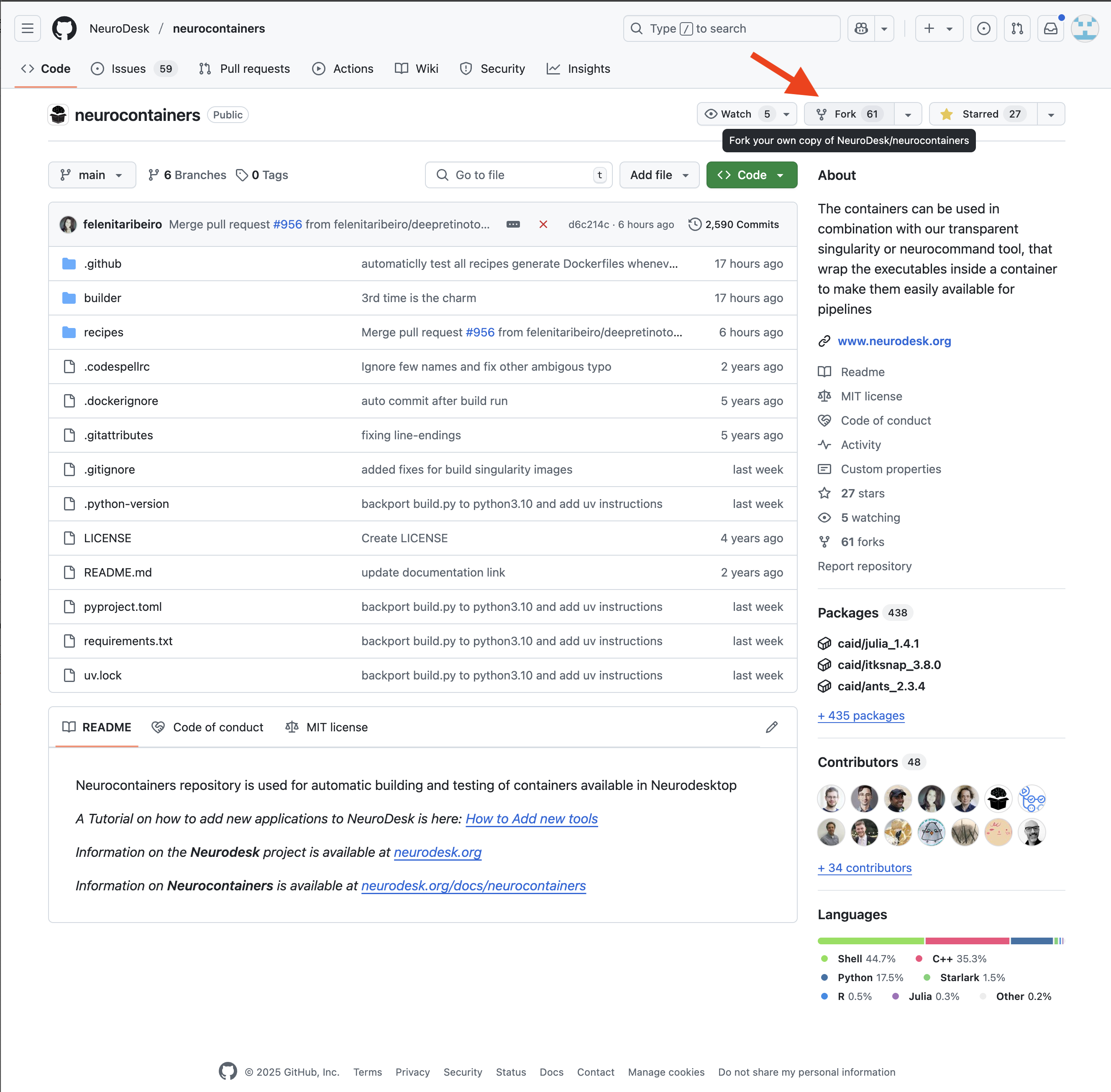
2. Fork the repository
You will then need to fork the Neurodesk repository to your own repositories. This allows you to make changes independently and propose updates.
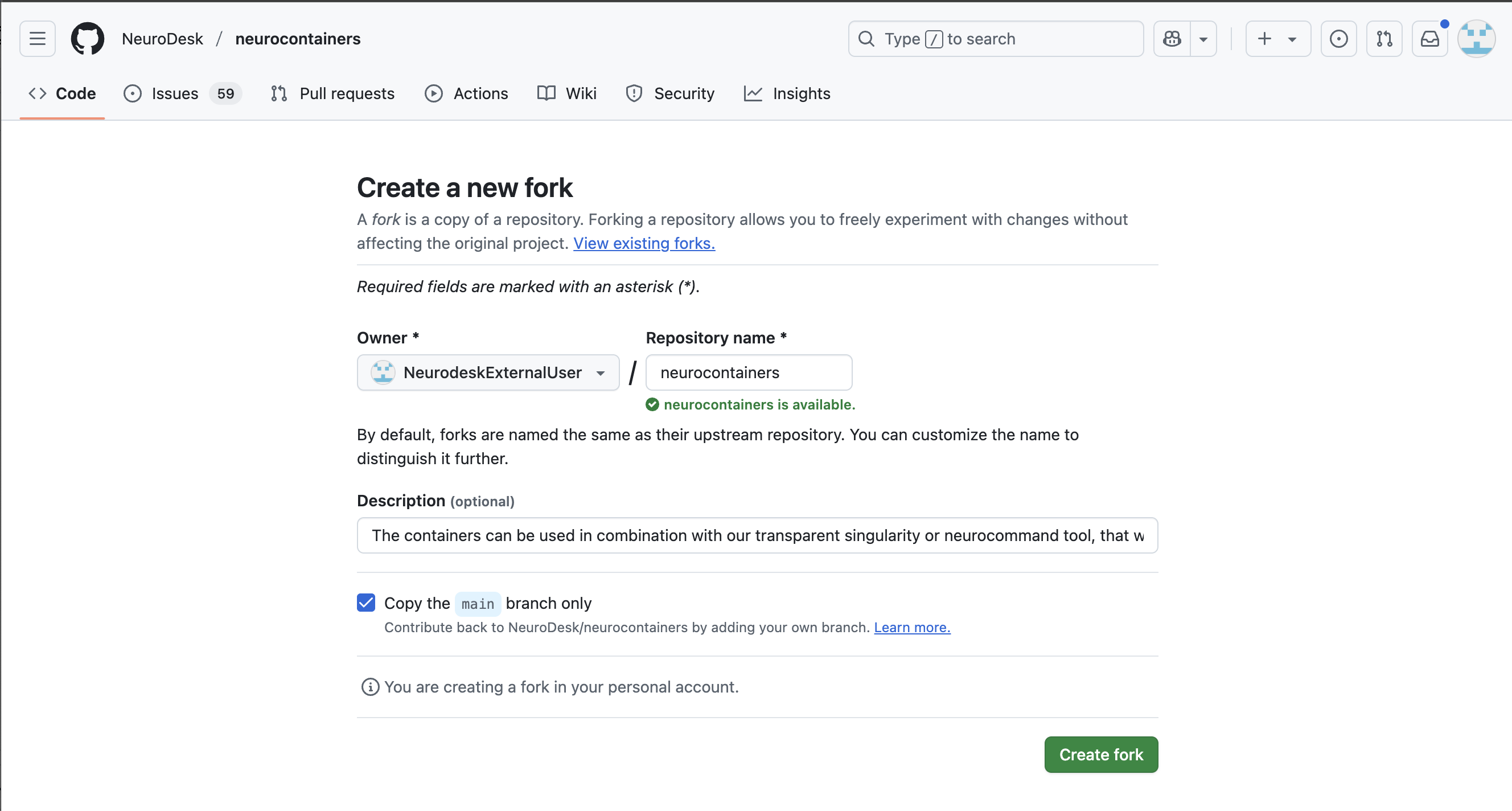
Naming your repository
You may decide to keep the same name for your new reposoitory, or you may rename it.
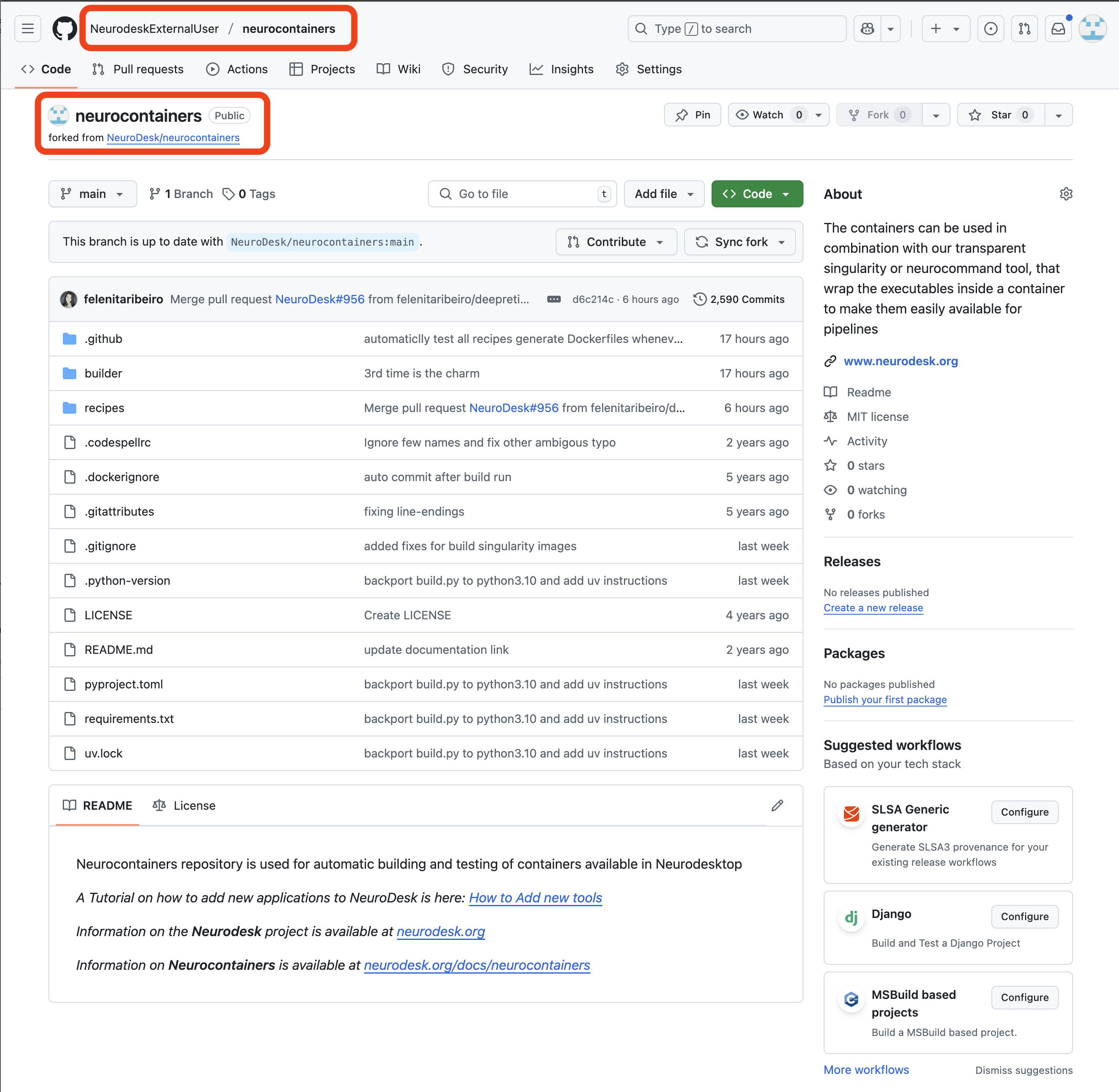
Confirming you are on the forked version
In the top left corner, you can see that you are in your forked repository of the neurocontainers repository.
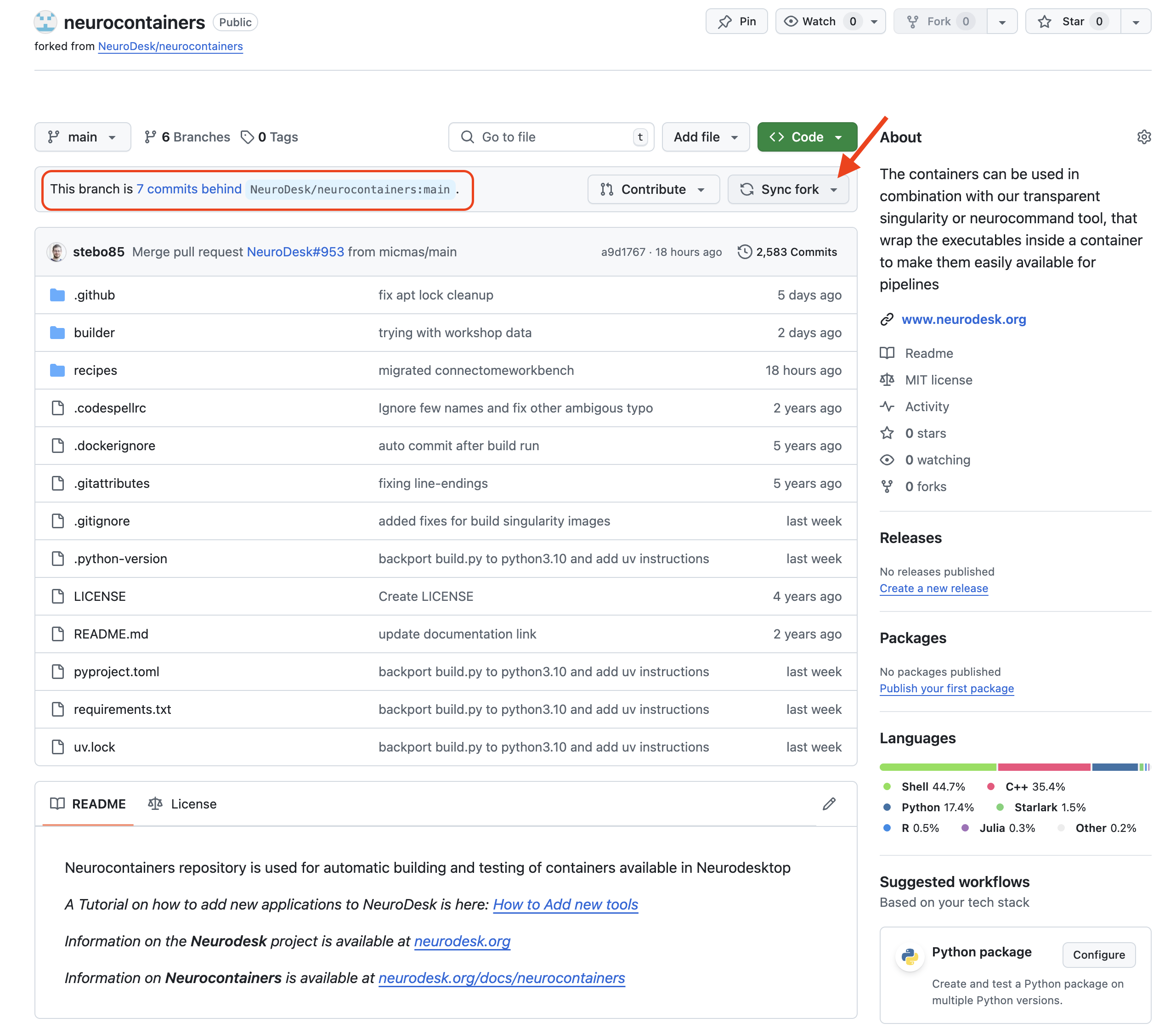
Keeping your forked repository up-to-date
If changes are commited to the Neurodesk/neurocontainers repository, you will see a banner saying you are N commits behind. You may decide to Sync fork, which will update your repository, allowing you to have the most up-to-date files.
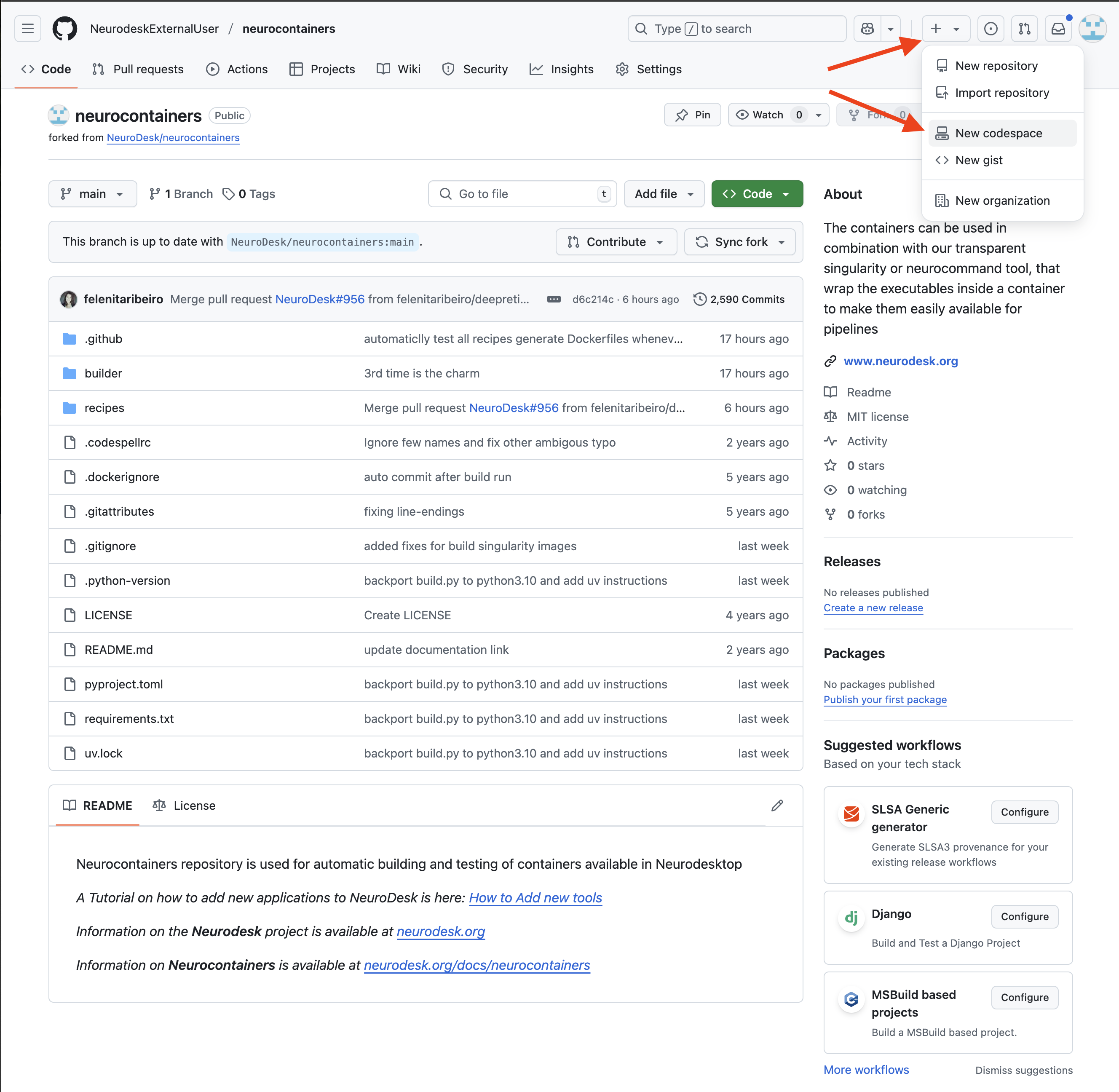
3. Create and Edit a Codespace
Once this is done, you will want to start a Codespace using by:
- Clicking the + (Create new…) button in the top right corner. (it’s a + sign button)
- Selecting Codespaces > New codespace.
Configure your Codespace.
Resource recommendation:
Most neurocontainers run smoothly on a 2-core machine. For containers with heavier computational demands, consider using a 4-core machine.
This opens an editable environment directly in your browser.
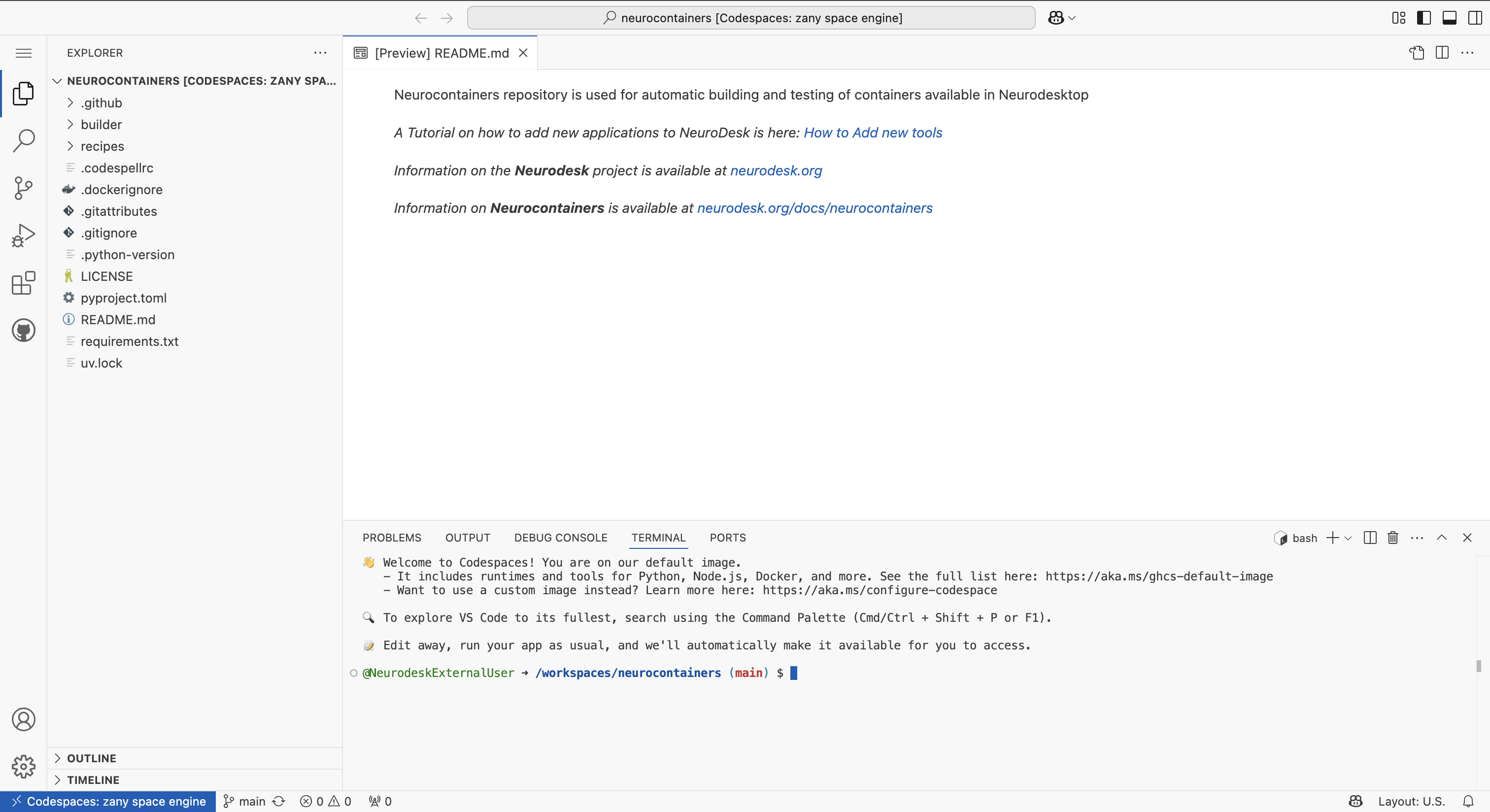
In the terminal, run the following lines to configure your codespace environment.
python3 -m venv env
source env/bin/activate
pip install -r requirements.txt
This will install a series of packages to allow you to make changes to neurocontainers.
YAML extension
The first time you use a codespace, you will also need to download the YAML extension by navigating to the Extensions tab using icon on the left of your screen and searching for YAML. Click the install button.
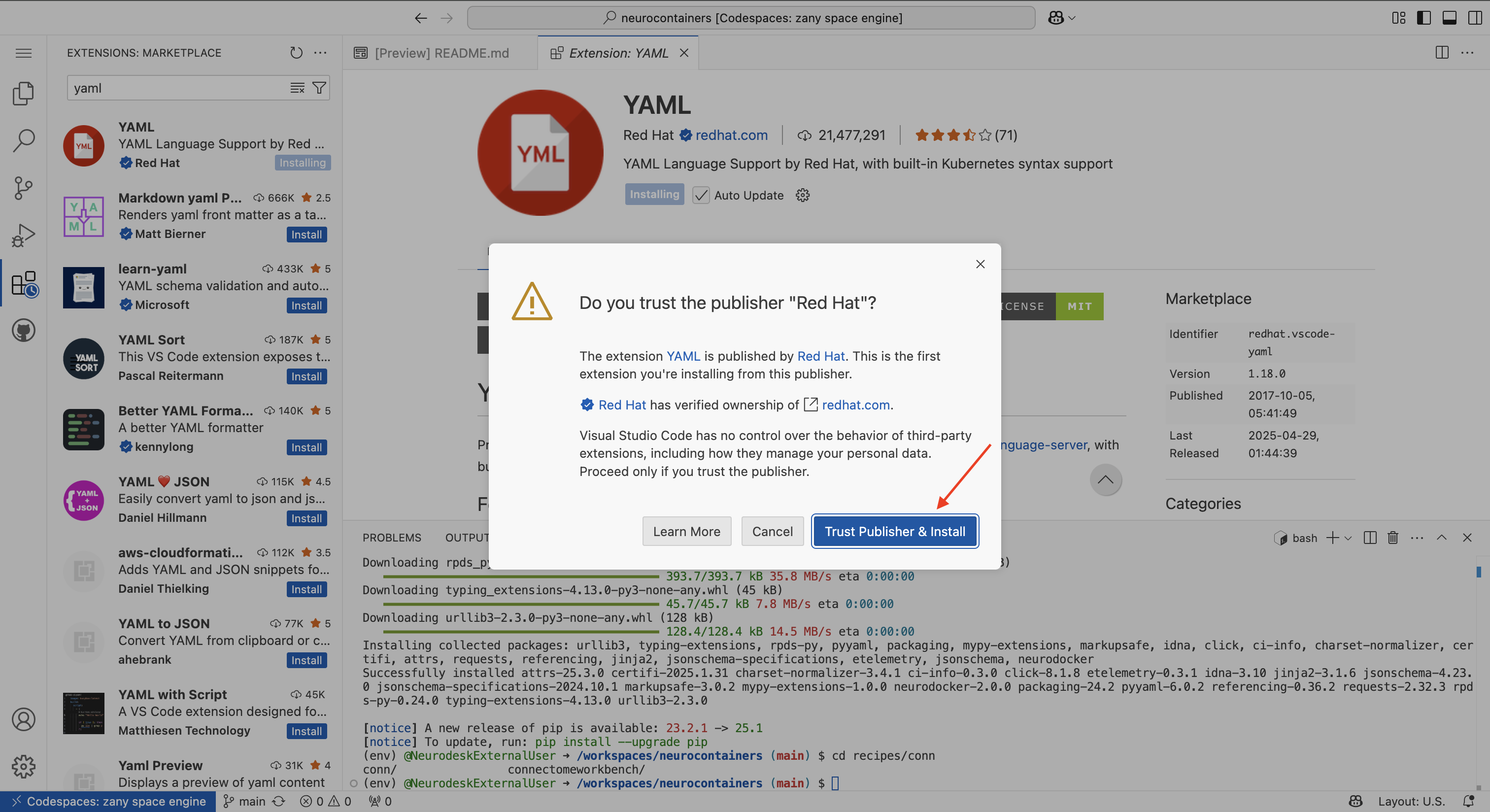
There will be a security pop-up where you will need to click “Trust Publisher & Install”
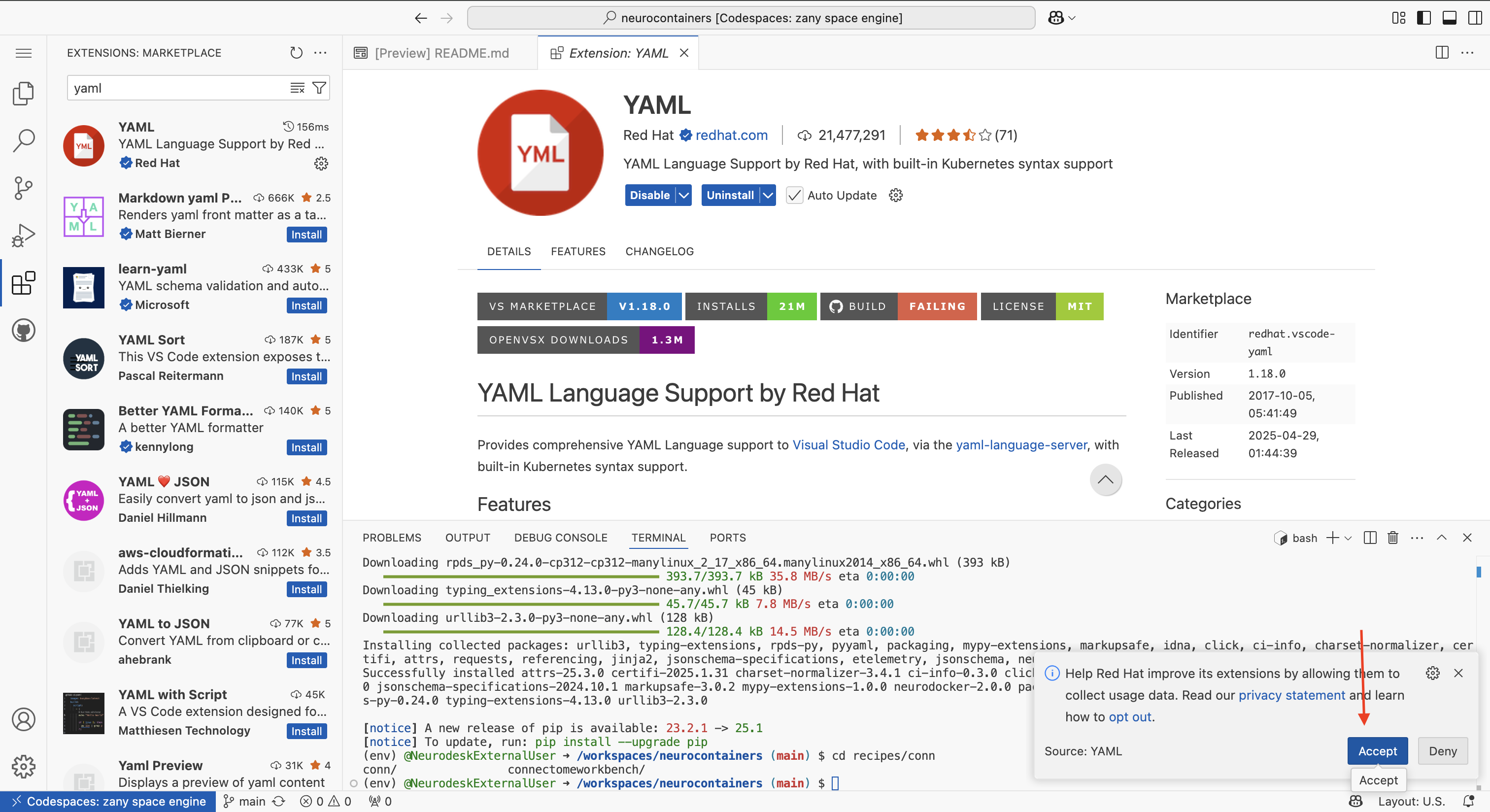
There will be another pop-up asking whether you allow the developers to collect data. You may click “Agree” or “Deny”
4. Make Changes to the desired Container
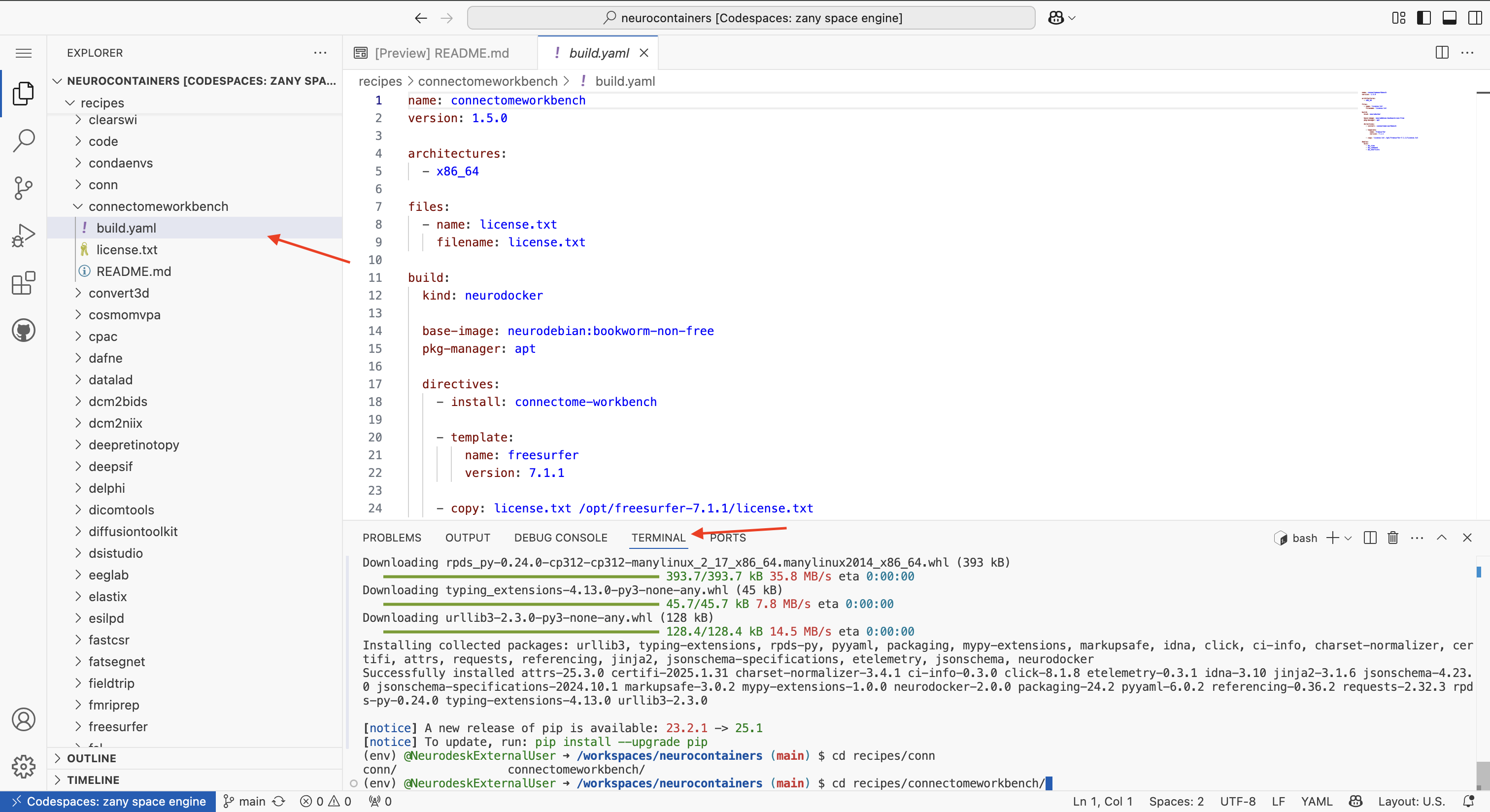
Navigate back to the Explorer tab using the icon on the left of your screen.
Using either the terminal at the bottom of your Codespace or the file browser on the left, navigate to the build.yaml file of the tool you wish to update.
Each tool has its own folder inside the recipes/ directory, and inside that folder, you will find the corresponding build.yaml file.
- Using the GUI (file browser): Navigate manually to
recipes/connectomeworkbench/. - Using the terminal, you can use:
cd recipes/connectomeworkbench/ #or whichever other neurocontainer you want to update
Editing the build.yaml
Open the build.yaml file. Make the necessary updates to:
- Software version numbers
- Dependencies
- Download links
- Build instructions (if needed)
In this example, when we go to the Connectome Workbench website, we can see that the latest version available is Connectome Workbench v2.0.1.
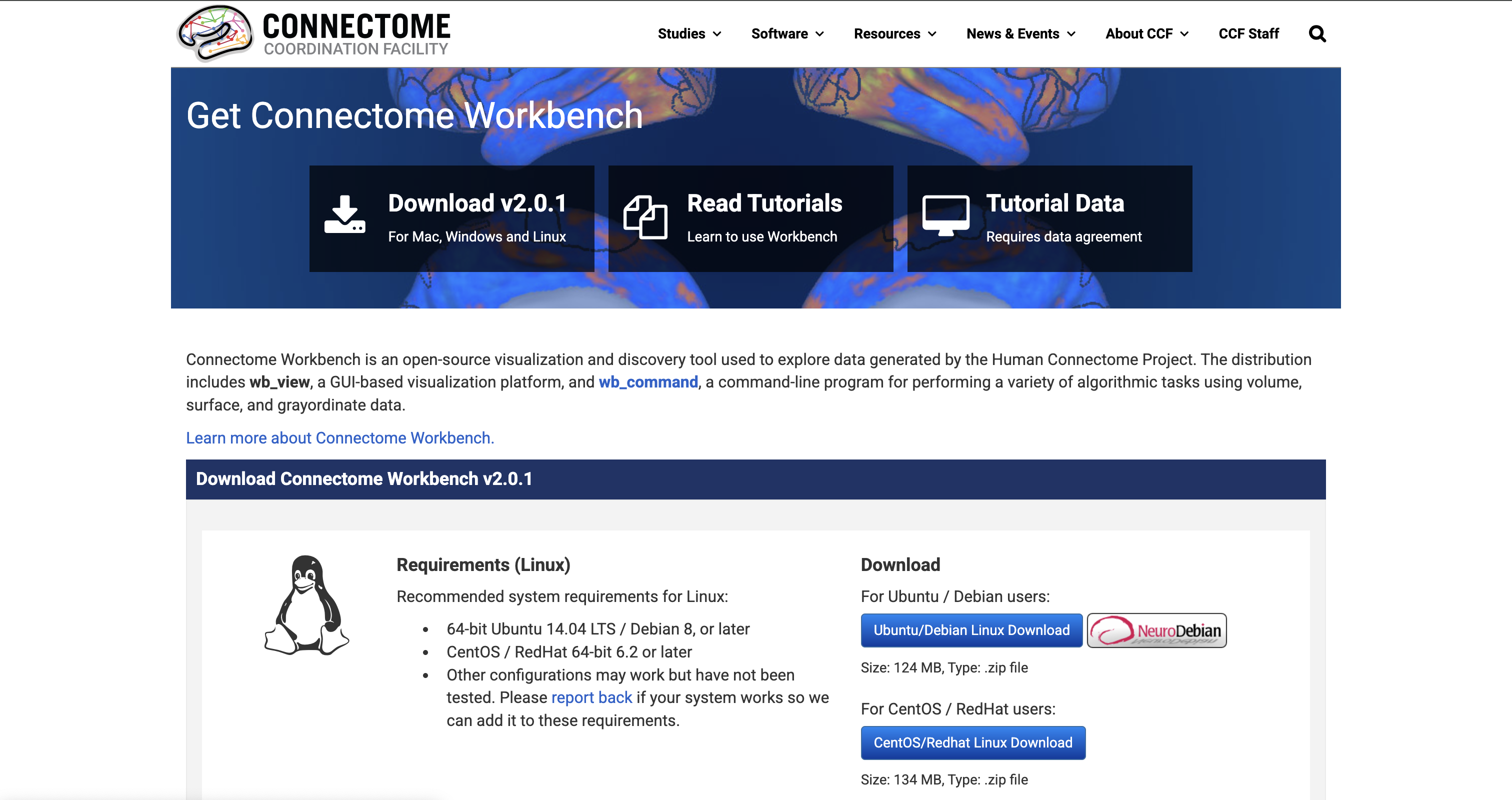
To update Neurocontainer version, simply change the version: to 2.0.1
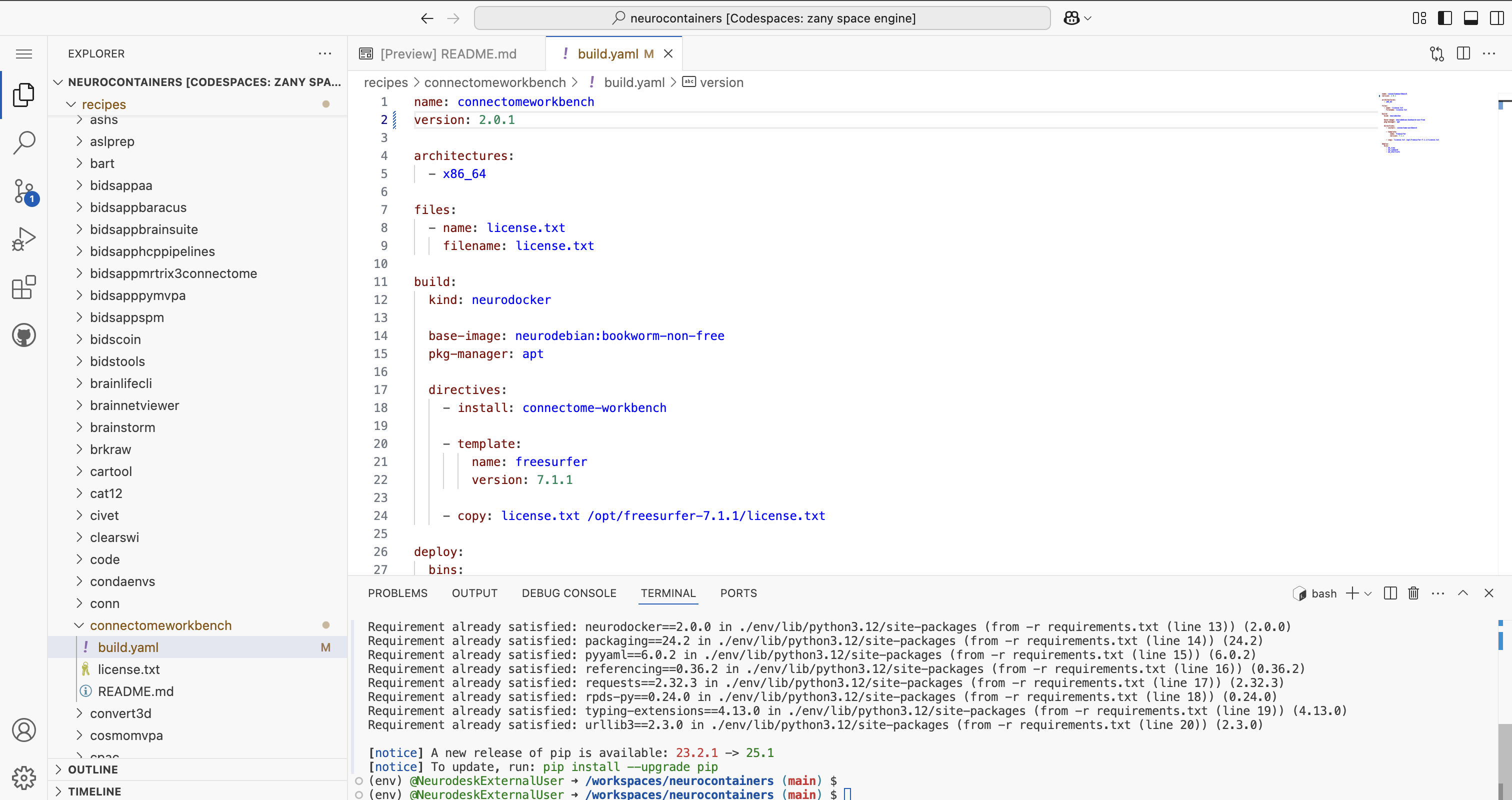
If you are unsure how to structure the build.yaml, please refer to the examples provided in the Neurocontainers builder documentation.
Important:
Keep your formatting strict! YAML files are indentation-sensitive. Use spaces, not tabs.
Once you have made your changes, save the file.
5. Validate Your Changes
Before committing, make sure your changes are valid.
In the terminal, run:
./builder/build.py generate connectomeworkbench #Replace connectomeworkbench with the name of the folder you updated
#This second step can take some time
./builder/build.py generate connectomeworkbench --recreate --build --test #Replace connectomeworkbench with the name of the folder you updated
This script will:
- Parse your
build.yaml - Check for syntax errors
- Show the build steps without actually building the full container
You will be able to see the progress for each of the building steps.
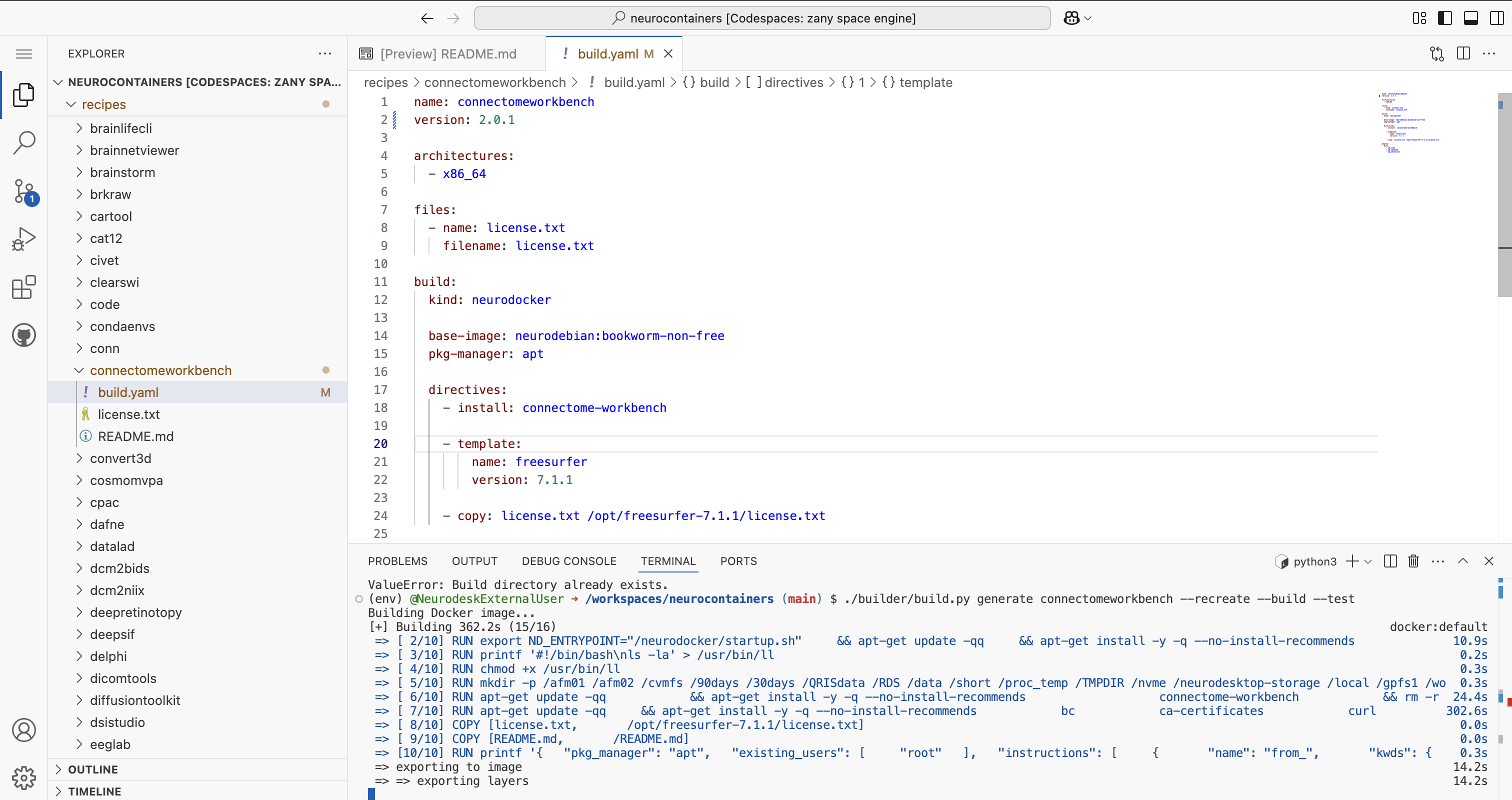
If there are errors, correct them before proceeding.
Once you see Docker image built successfully at connectomeworkbench:2.0.1, you are ready to commit and push your changes.
6. Commit and Push Your Changes
Once you have validated your build.yaml, it’s time to save and upload your work.
In the terminal:
to check which files were changed.
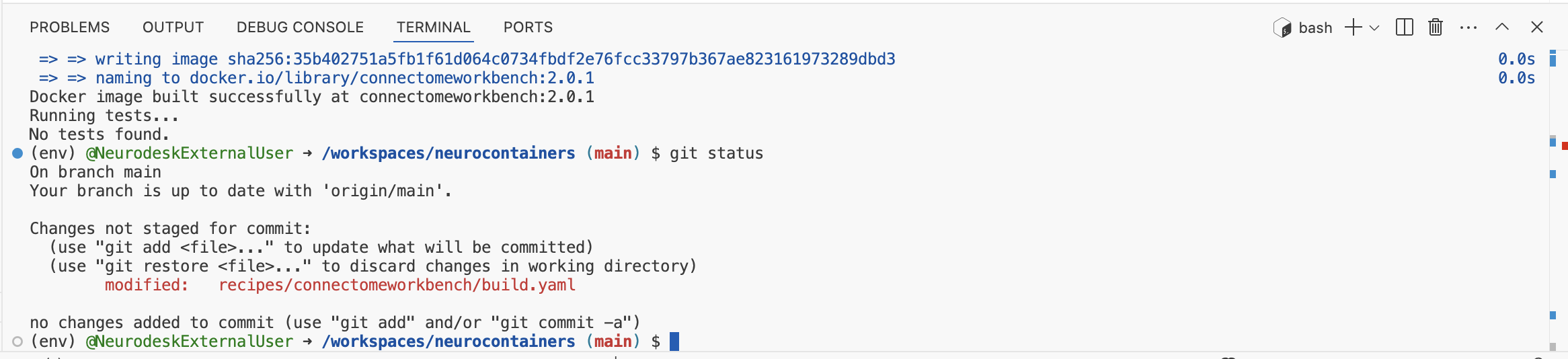
If only this reflects the changes you’ve made, then stage, commit, and push your changes:
git add recipes/connectomeworkbench/build.yaml #Replace connectomeworkbench with the name of the folder you updated
git commit -m "Update connectomeworkbench container: updated version 2.0.1" #Adapt commit message
git push
Make sure your commit message is clear and descriptive, for example:
Update Connectome Workbench container to version 1.5.0 Adjust the commit message based on the updates you made to the neurocontainer.
7. Create a Pull Request
After pushing your changes:
- Go back to your forked repository on GitHub.
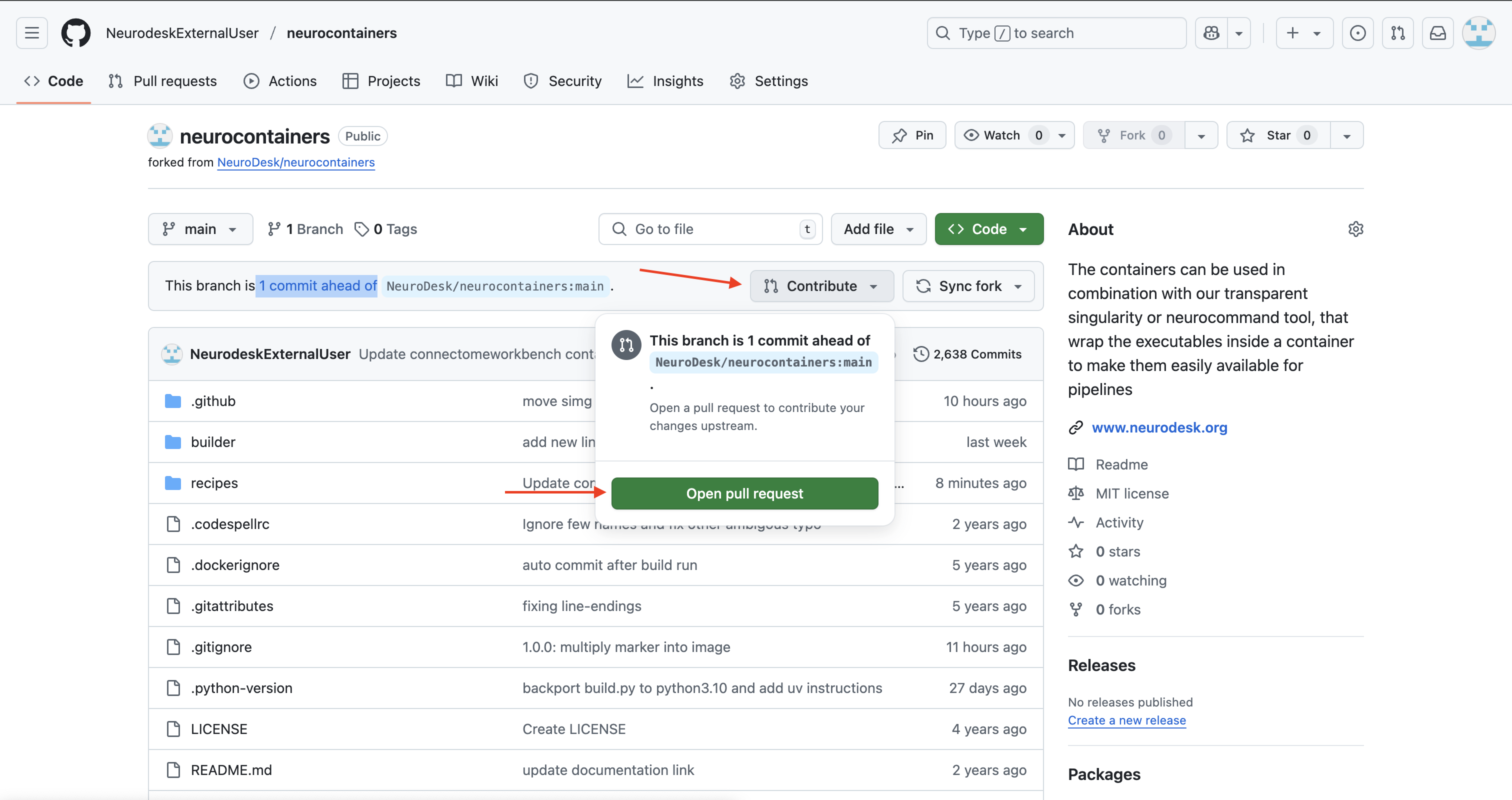
- You should see a banner saying “This branch is X commits ahead of
NeuroDesk/neurocontainers:main”.
You can either click on **X commit ahead of** to view the differences between your repository and the Neurodesk repository and then **Create pull request**
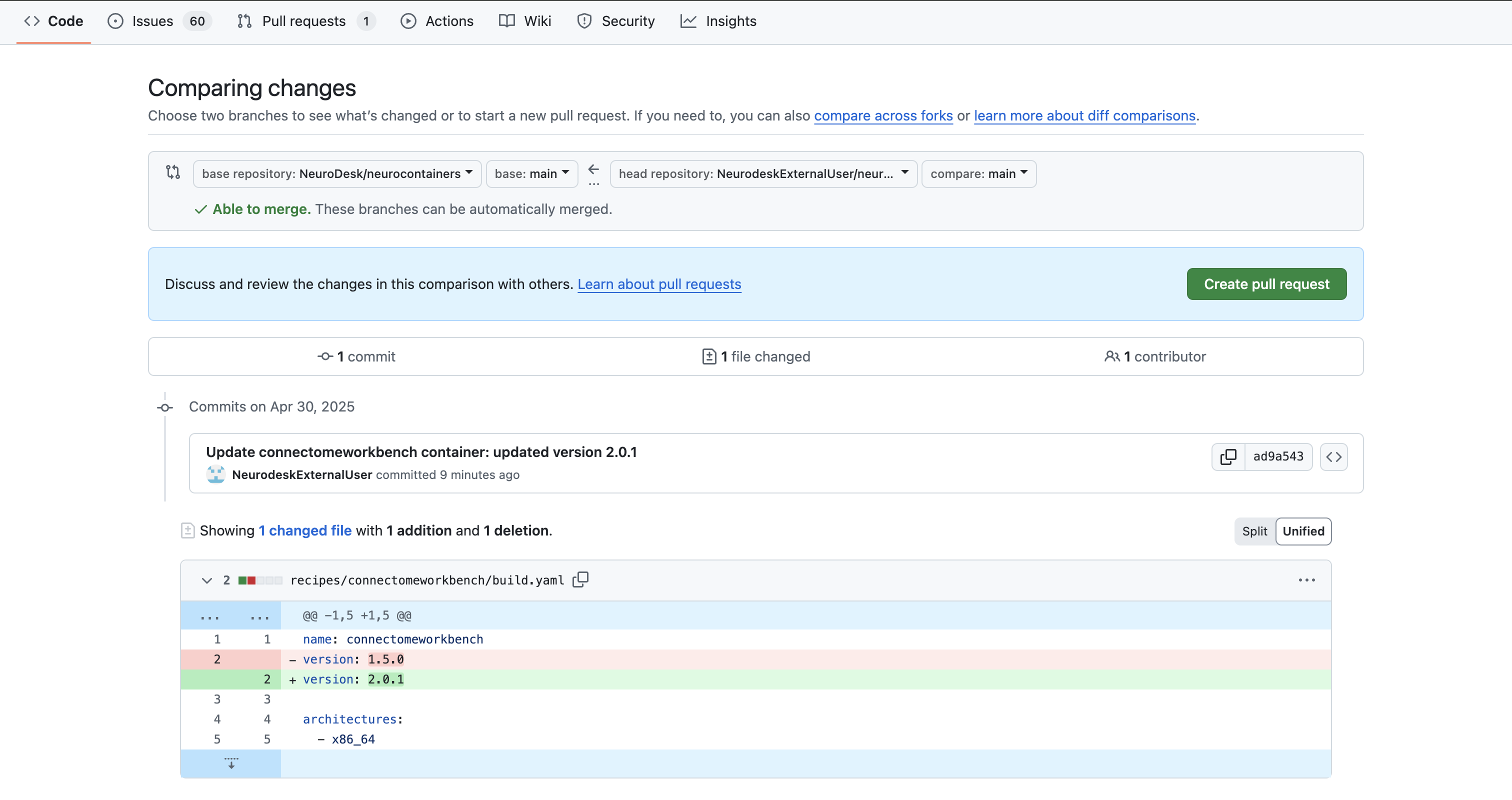
or
click on Contribute > Open pull request.
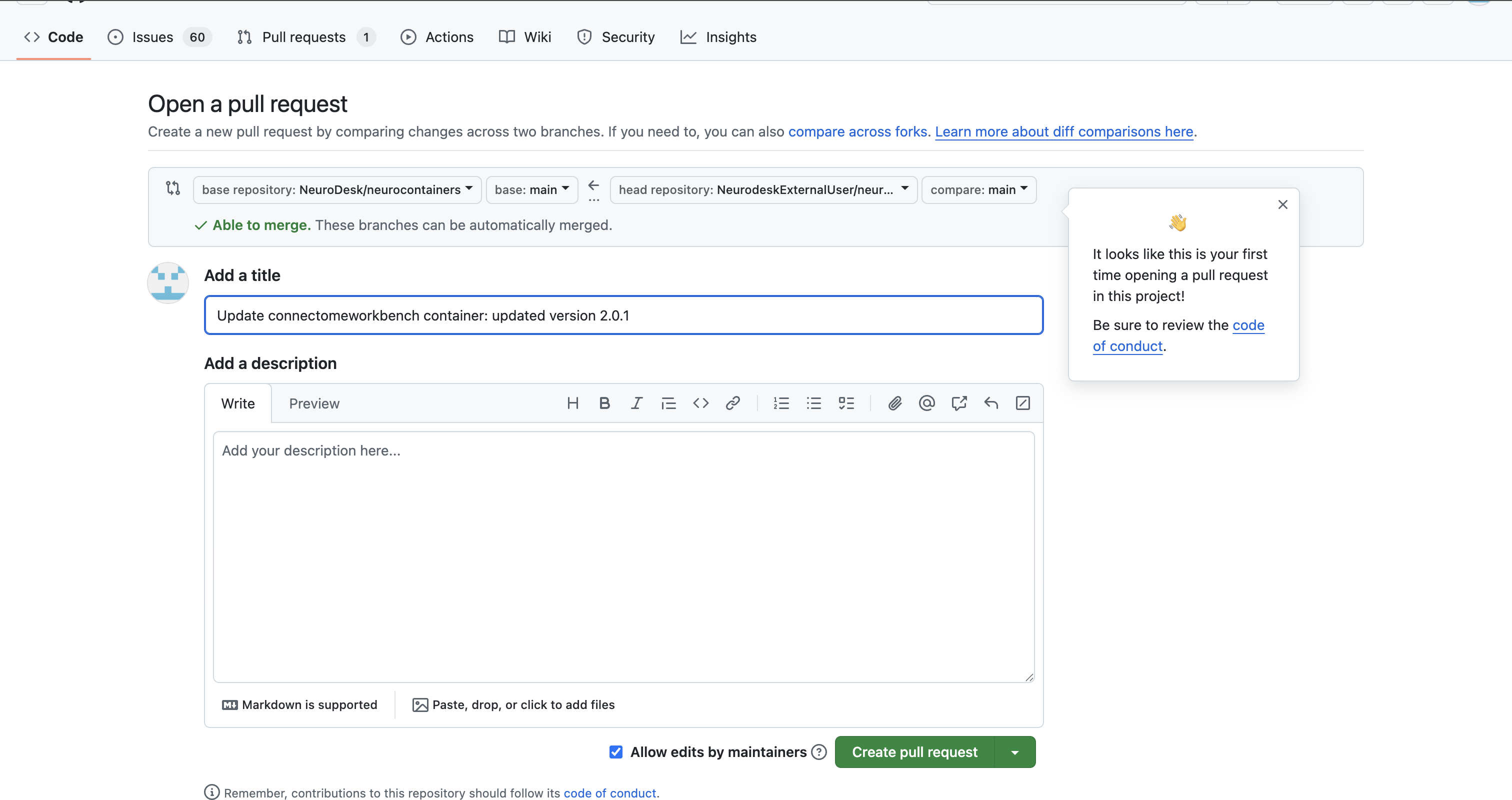
- In the Pull Request:
- Provide a clear title (e.g., Update Connectome Workbench to v1.5.0)
- Write a brief description of what you changed (version bump, new dependencies, etc.)
- Create the pull request.
Our Neurodesk team will review your proposed update, test the updated container to make sure it work and merge your changes to Neurodesk if everything works correctly, allowing all users to benefit.
More detailed documentation can be found here: https://github.com/NeuroDesk/neurocontainers/tree/main/builder
Need Help?
If you have questions or would like feedback before submitting:
We appreciate your contribution to the Neurodesk community and reproducible science.